We are in the age of Big Data, and there are a bunch of technologies and startups popping up all over the world that deals with Big Data. One of the hottest and fastest growing technologies is Apache Spark.
Apache Spark is a completely open sourced, scalable data analytics and cluster computing framework. Apart from general analytics, it also features exciting Machine Learning capabilities with Spark MLLib, SQL-Like queries with SparkSQL, support for large graphs with GraphX, and streaming capabilities with Spark Streaming.
Why Apache Spark?
- The USP of Spark is that it is “lightning” fast. It claims to be a 100x faster than Hadoop’s MapReduce for some applications
- (This is my favorite reason) It supports not 1, not 2 but 3 languages: Scala, Java and Python! You can now write terse python or scala code in seconds. For instance, the ubiquitous word-count example is a just single line in Python / Scala.
- Spark’s data structures – called Resilient Distributed Dataset (RDDs) has inbuilt fault tolerance.
- Spark’s API is more basic (or primitive) than Hadoop’s MapReduce – allowing you to build more general applications from the ground up and freeing you from the MR constraint that Hadoop enforces; at the same time map reduce APIs are retained.
- It has an interactive shell. This will allow users to play around with data and makes debugging big-data applications very easy
- It integrates with Hadoop easily
- The Spark sub-projects – MLLib, SparkSQL, GraphX, Spark Streaming offer a wealth of features
- Last but not the least, it a has great community (mailing lists, friendly people on IRC, https://spark.apache.org/community.html)
Machine Learning on Spark
MLlib is Spark’s scalable machine learning library consisting of various commonly used algorithms. It is an alternative to other scalable Machine Learning libraries for Big Data, such as Apache Mahout.
It has plenty of algorithms to choose from, ranging from simple summary statistics, to complex learning algorithms like Decision Trees.
The following main categories of algorithms can be assumed:
- Classification – Categorize your data into predefined categories. Eg: Credit Approval
- Regression – Predict a real-valued variable given some data. Eg: Churn Prediction
- Recommendation – Recommend relevant products based on history. Eg: Predicting “Recommended Items” in a E-Commerce site based on user click-stream.
- Clustering – Recognize patterns in Data. Eg: Customer Segmentation
Spark supports popular algorithms like Naive Bayes, Decision Trees, Support Vector Machines, Alternating Least Squares, among others. Apart from that, it also provides bare-bones optimization algorithms if you’re in the mood to write your own Machine Learning algorithms!
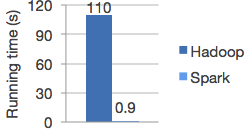
Plus, it’s super fast: (This is for Logistic Regression)
Spark-SQL
Data comes in all sizes and If your data happens to be very large, then you’re out of luck if you happen to use SQL. If you transition to using Hadoop to store your data, then you lose the ability to query your data like you used to. Hive, Impala, are all answers to that conundrum.
But all of those run on Hadoop! With Spark-SQL you can run queries on Spark and take advantage of it’s speed and ease of use. If you’re already using Hive, you can make a switch easily to Spark-SQL, since it also supports HiveQL.
Spark-SQL is fully fault-tolerant, and also allows you to cache tables in memory – a useful feature for frequently-accessed tables.
Easy, Realtime Data Processing with Spark Streaming
Spark Streaming makes it easy to build scalable fault-tolerant streaming applications. It is easy to use and has all of Spark’s inbuilt fault tolerance.
It features lightweight but fast APIs, and offers ‘exactly-once’ semantics out of the box – something that other technologies like Apache (Twitter) Storm does not offer.
A great feature of Spark Streaming is that you can use the same code for streaming and batch operations.
GraphX
Spark’s GraphX library allows you to seamlessly work with both graphs and collections.
With comparable runtimes to other Graph Libraries like GraphLab and Giraph, GraphX also retains Spark’s immense flexibility, fault-tolerance and speed.
It has common algorithms for most common requirements of internet-scale graphs, including PageRank. It also has a very flexible API, which allows you to use it effectively.
Summary
Spark is certainly taking over – Cloudera, Yahoo, Impetus are a few companies to have jumped on the Spark bandwagon. I quote from this article :
Since its introduction in 2010, Spark has caught on very quickly, and is now one of the most active open source Hadoop projects–if not the most active. “In the past year Spark has actually overtaken Hadoop MapReduce and every other engine we’re aware of in terms of the number of people contributing to it”
If
- You have a considerable amount of Data
- You need to perform possibly complex analytics on the data
- You need to get it done fast
- You need scalable Machine Learning
Then Spark is your answer.